เนื้อหาที่เข้าร่วมอบรมเชิงปฏิบัติการโดย Professor Nagaray, Dr. George Ostrouchov และ Dr. Andrew M. Raim แยกเนื้อหาการอบรมเชิงปฏิบัติการได้ดังรายละเอียดต่อไปนี้
Introduction to Big Data and Why R?
วิทยากรได้อธิบายถึงความรู้เบื้องต้นเกี่ยวกับข้อมูลขนาดใหญ่ (Big Data) โดยกล่าวถึงวิวัฒนาการของการเกิดขึ้นของข้อมูลขนาดใหญ่ อาทิ ข้อมูลที่ได้จากเซนเซอร์ (sensors) ของดาวเทียม ข้อมูลเกี่ยวกับชั้นบรรยากาศ ข้อมูลที่ได้จากกล้องจุลทรรศน์ (microsopy) ข้อมูลนิวตรอน (neutron science) ข้อมูลทางด้านธุรกิจ ข้อมูลทะเบียนราษฎร์ของรัฐบาล ข้อมูลภาษี ข้อมูลจากอินเตอร์เนต เป็นต้น จากนั้นวิทยากรได้ชี้ถึงความสำคัญของข้อมูลว่าเป็นรากฐานที่สำคัญวิทยาศาสตร์และวิวัฒนาการของนักสถิติในการจัดการและวิเคราะห์ข้อมูล เป็นต้น


Introduction to R
วิทยากรได้อธิบายถึงความรู้เบื้องต้นเกี่ยวกับโปรแกรมอาร์ (R-programming) ซึ่งเป็นซอฟต์แวร์ที่อนุญาตให้ใช้ได้โดยไม่ต้องเสียค่าใช้จ่ายใด ๆ ภายใต้ลิขสิทธิ์แบบ GNU General Public License ในรูปรหัส source code โดยโปรแกรมอาร์ ยังเป็นซอฟต์แวร์ที่รวมเอาคุณสมบัติด้านการจัดการข้อมูล การคำนวณ และการแสดงทางกราฟิกไว้ด้วยกันอย่างดี โดยวิทยากรได้อธิบายถึงสภาพแวดล้อม (Environment) ของโปรแกรมอาร์ว่ามีอะไรบ้าง อาทิ มุมมองของโปรแกรมที่เรียกว่า R-GUI โปรแกรมมีสภาพแวดล้อมแบบ object oriented ซึ่งหมายถึงสิ่งต่าง ๆ ที่อยู่ในหน่วยความจำของโปรแกรมอาร์ จะเป็นวัตถุที่จะต้องมีชื่อกำกับเสมอ อีกทั้งโปรแกรมอาร์ยังมีข้อดีที่เป็นจุดเด่น คือ มีโปรแกรมประยุกต์ (package) ที่ผู้ใช้โปรแกรมอาร์ทั่วโลกเขียนขึ้นมาเพื่อใช้เฉพาะเรื่องเป็นจำนวนมาก ผู้ใช้อื่น ๆ สามารถนำโปรแกรมประยุกต์ดังกล่าวมาใช้ได้เลยโดยไม่ต้องกังวลเรื่องลิขสิทธิ์ จากนั้นวิทยากรได้อธิบายถึงคำสั่งเบื้องต้นต่าง ๆ ที่ใช้ในโปรแกรมอาร์ อาทิ คำสั่ง help รูปแบบคำสั่งการกำหนดวัตถุ คำสั่งการคำนวณต่าง ๆ คำสั่งเมทริกซ์ (Matrices) คำสั่งเวคเตอร์ (vectors) คำสั่งอเรย์ (array) คำสั่งเงื่อนไขการเปรียบเทียบ เช่น if then else เป็นต้น นอกจากนั้นวิทยากรได้แนะนำโปรแกรมเพิ่มเติมอื่น ๆ ที่ใช้ร่วมกับโปรแกรมอาร์ โดยจะทำให้การทำงานของโปรแกรมอาร์มีประสิทธิภาพมากยิ่งขึ้น เช่น R Studio ซึ่งเป็นโปรแกรมในกลุ่ม Integrated Development Environment (IDE) ที่นำมาจัดรูปแบบมุมมองของโปรแกรมอาร์ให้สามารถใช้งานได้ง่ายขึ้น ร่วมถึงยังโปรแกรมประยุกต์ที่สำคัญที่จะอำนวยความสะดวกในการจัดการและวิเคราะห์ข้อมูล อาทิ R Commander ที่อำนวยความสะดวกโดยการสร้างสภาพแวดล้อมแบบเมนูและเลือกใช้, Rattle ที่อำนวยความสะดวกในการจัดการเหมืองข้อมูล (data mining) จากนั้นวิทยากรได้ให้ผู้เข้าร่วมการอบรมได้ใช้คำสั่งต่าง ๆ ในการจัดการและวิเคราะห์ข้อมูล เช่น การแจกแจงข้อมูล (distributions) การพรรณนาข้อมูล (descriptive statistics) และการอนุมานเบื้องต้น (basic inference)
Basic Data Analysis
วิทยากรได้อธิบายและนำผู้เข้าร่วมการอบรมใช้โปรแกรมอาร์และโปรแกรมประยุกต์ ในวิเคราะห์ข้อมูลขนาดใหญ่โดย โดยใช้วิธีการทางสถิติ อาทิ การวิเคราะห์การถดถอย (regression) การวิเคราะห์ตัวแบบเชิงเส้นทั่วไป (general linear model: GLM) การวิเคราะห์การจำแนก (classification) การวิเคราะห์การจำแนกและการถดถอยแบบต้นไม้ (classification and regression trees) การวิเคราะห์ random forest การวิเคราะห์การแบ่งกลุ่ม (clustering) การวิเคราะห์ส่วนประกอบหลัก (principal components analysis) การวิเคราะห์เครือข่าย neural เป็นต้น
Getting your data into R
วิทยากรได้อธิบายและนำผู้เข้าร่วมการอบรมใช้โปรแกรมอาร์และโปรแกรมประยุกต์ rattle ในการนำเข้าข้อมูลที่อยู่ในรูปแบบไฟล์ต่าง ๆ อาทิ CSV files, Binary files (rhdf5), SQL databases, SAS (sas7bdat) และ Big datasets โดย
Evaluating Variability and Uncertainty
วิทยาการได้อธิบายและนำผู้เข้าร่วมการอบรมใช้โปรแกรมอาร์ในการประเมินความผันแปรและความไม่แน่นอนของข้อมูล ด้วยวิธีการ Bootstrap, Cross-validation โดยการโปรแกรม (writing code)
Graphics
วิทยาการได้อธิบายและนำผู้เข้าร่วมการอบรมใช้โปรแกรมอาร์ในการสร้างรูปแผนภาพต่าง ๆ เพื่อใช้ในการวิเคราะห์ข้อมูลโดยใช้ Traditional Graphics, ggplot2 และใช้ knitr ดังรูปภาพตัวอย่าง

Parallels
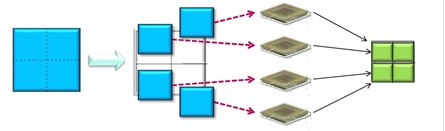
วิทยาการได้อธิบายถึงหลักการของโปรแกรมแบบขนาน ซึ่งมีจุดประสงค์ทำให้โปรแกรมทำงานได้เร็วขึ้น โดยเฉพาะการวิเคราะห์ข้อมูลขนาดใหญ่ (big data) โดยอยู่บนหลักการที่ว่ามีการแบ่งงานใหญ่เป็นงานย่อย ๆ หลาย ๆ งาน จากนั้นส่งงานย่อไปทำงานยังเครื่องประมวลผลหลาย ๆ เครื่องพร้อมกัน แล้วจึงทำการรวบรวมผลที่ได้จากเครื่องประมวลผลต่าง ๆ ดังภาพด้านล่าง
โดยวิทยากรได้นำโปรแกรมประยุกต์ที่ใช้ในโปรแกรมอาร์มาใช้ อาทิ pdbR จากนั้นวิทยากรได้สาธิตและให้ผู้เข้าร่วมอบรมวิเคราะห์ข้อมูลแบบขนาน อาทิ Parallel Bootstrap, Parallel Cross-validation และ Parallel randomForest เป็นต้น รวมทั้งการนำเข้าข้อมูลขนาดใหญ่ด้วยการโปรแกรมแบบขนานด้วย อาทิ Parallel CSV file input, Parallel HDF5 file input และ Parallel ADIOs file input รวมถึงการสร้างโปรแกรมคู่ขนานในการจัดการเมทริกซ์ขนาดใหญ่ให้มีความรวดเร็วในการประมวลผลด้วย เป็นต้น