Modern Documentation Data Modelling Beyond the AI Era จะกล่าวถึงการเปลี่ยนแปลงด้านการจัดเก็บข้อมูลในยุค AI ซึ่งจะมีการเปลี่ยนจากระบบฐานข้อมูลเชิงสัมพันธ์ไปเป็น แบบจำลองข้อมูล (Data Modeling) เนื่องจากการทำ AI ต้องเก็บข้อมูลในรูปแบบตัวเลข (Vector) ดังนั้นโปรแกรมฐานข้อมูลที่นำมาใช้จะต้องรองรับข้อมูลขนาดใหญ่ที่อยู่ในรูปเอกสารข้อความ (Text) ตัวเลข (Number) ตัวเลขเวคเตอร์ (Vector) คำอธิบายชุดข้อมูล (Metadata) โปรแกรมฐานข้อมูลที่นิยมนำมาใช้ได้แก่ Mongo DB เนื่องจากมีความยืดหยุ่นรองรับ Vector Data Model เช่น
- Embedding Data Model -ลดการเชื่อมต่อที่ซับซ้อน
- Simple Pattern
- Attribute Pattern (Key and value)- ช่วยลด attributeในการค้นหา
- Extended Reference Pattern -อ้างอิง attribute โดยไม่สนใจข้อมูลที่ซ้ำ
- The outlier Pattern จัดการข้อมูลขนาดใหญ่
- Bucket Pattern เก็บประวัติการสนทนา
ตัวอย่าง Embedding Data Model ช่วยหลีกเลี่ยงการเชื่อมต่อที่ซับซ้อนระหว่างคอลเลกชันหลายรายการ ในขณะเดียวกันก็ช่วยปรับปรุงประสิทธิภาพและลดภาระงานในการใช้งาน
{
“topic”: “ ปี 2026 มือถือยี่ห้อไหน มีน้ำหนักเบา”
“topic_vector”: [0.123, -0.456, 0.789, 0.012,…]
“topic_comments”: [
{“user”: “JoJoBar”, “Comment”, “EyePhone Ah 9”},
{“user”: “kaken”, “Comment”, “Somesongs Slim 10”},}
]
}
นอกจากนี้ MongoDB Vector ยังใช้ในการเพิ่มประสิทธิภาพการค้นหาแสดงในรูปแบบ ANN, ENN, k-NN ปัจจุบัน Facebook ได้ใช้ Mongo DB ในการจัดเก็บข้อมูล
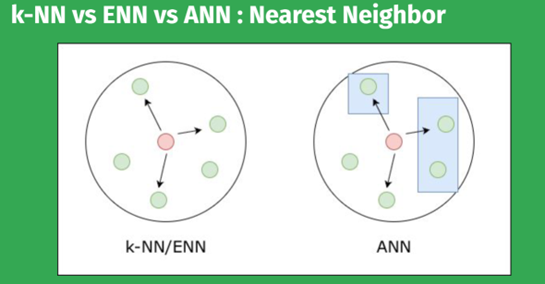
|
คุณสมบัติ
|
k-NN / Exact-NN (ENN)
|
Approximate-NN (ANN)
|
|
ความแม่นยำ
|
100% (ได้จุดที่ใกล้ที่สุด)
|
90-99%(มีโอกาสพลาดเล็กน้อย)
|
|
ความเร็ว
|
ช้ามาก (เมื่อข้อมูลเยอะ)
|
เร็วมาก (คงที่แม้ข้อมูลมหาศาล)
|
|
การใช้งาน
|
งานวิจัย, ข้อมูลขนาดเล็ก
|
ระบบ Search, ChatGPT, YouTube
|
|
เปรียบเทียบ
|
เดินวัดสายวัดทีละจุด
|
มองด้วยตาเปล่าแล้วกะระยะเอา
|
ข้อมูลเพิ่มเติม
- https://www.mongodb.com/docs/manual/data-modeling
- https://www.mongodb.com/docs/atlas/atlas-vector-search/vector-search-overview/